Database storage engines
Book Reference: DDIA

There are two categories of the storage engine
- LSM storage engine
- Page oriented storage engine (B-Tree based)
World’s simplest database
Script:
set(key, value) { echo "${key},${value}" > test.db}get(key) { grep "^${key}," test.db | sed -e "s/^${key},//" | tail -n 1}
What kind of values can be stored in the database defined by the above script?
It’s a key-value store where value can be of any type.
Write Performance

DB set is appending the record at the end of the file, Complexity O(1). It’s a very good performance.
Read Performance
In the worst case, to search for a record have to go through all the records in the database. Time complexity is O(n)
How to improve read performance?
Index
The index is built on the primary content, doesn’t affect any content. But it impacts the performance of the query.
- A well-chosen index improves the read performance
- Every index reduces the write performance.
Hash Index
You want to meet your friend, you know his society name but you forgot the apartment number.

One way is to go to every home and ask if that house belongs to your friend. Worst-case O(N)
Another way is to go to the society’s office and ask for the house number of your friend based on his name. That’s how a hash-based index works.
Hash-based index maps the key to the location where the value is stored.

Real-life Example:
- Bit cask (default storage engine of Riak DB) uses hash-based indexing.
- Bit cask offers high-performance reads and writes subjected to all keys fits in available RAM.
Segmentation, Merge, and Compaction
Disk out of space
Write operation appending at the end of the file, it keeps getting larger and larger and it will run out of space after a time.

Segmentation
When file size increases a threshold, close the file for further writes and create a new segment file for write.
Compaction
Throwing away the records corresponding to the duplicate one and keeping only the latest one.
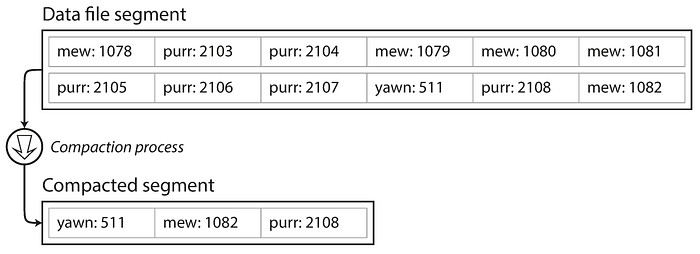
Merge
Segmentation and compaction will keep on increasing the number of segments. So periodically merge them.

Compaction and Merging happen in the background thread.
Problems in real database Implementation
File Format: CSV v/s binary format

Deleting records: Tombstone is added to mark a record as deleted.

Crash recovery: Memtable crash can be restored from the segment logs on the crash, it won’t be sorted.

Partially written records: Partially written records can be avoided with the help of the checksum.
Concurrency control: Keep a single writer thread.
Advantage of the hash-based index
- Writes are faster
- Concurrency and Crash recovery is better
Hash-based index drawback
- Range-based queries are inefficient
- The hash-based index should fit in memory
SSTable and LSM
SSTable stands for Sorted String Table.
In SSTable, simple change to our segments file, keys are stored in the sorted order.
Construction of SSTable
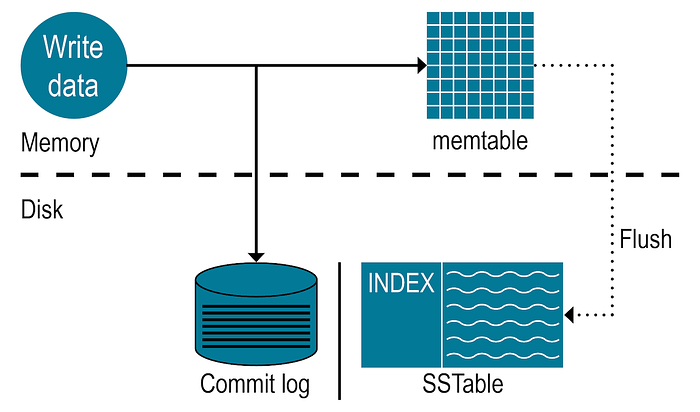
Questions: Explain the following flows in SSTable
- Write to memtable
- Write to segment
- Read
- Crash recovery
Advantages of SS table
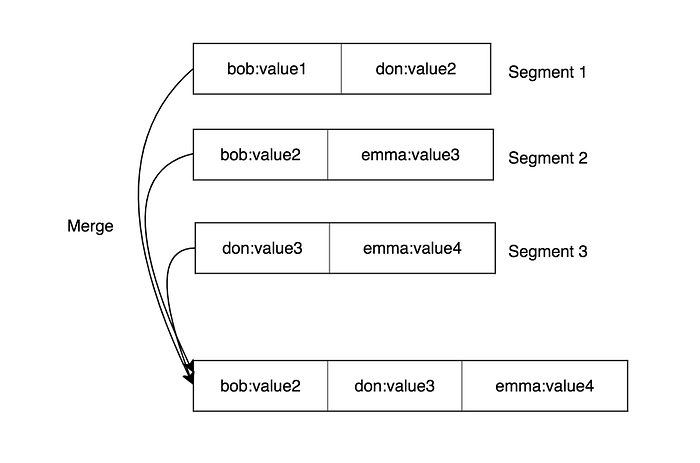
- Merging and compaction are easier: Based on merge sort.
- Index is sparse
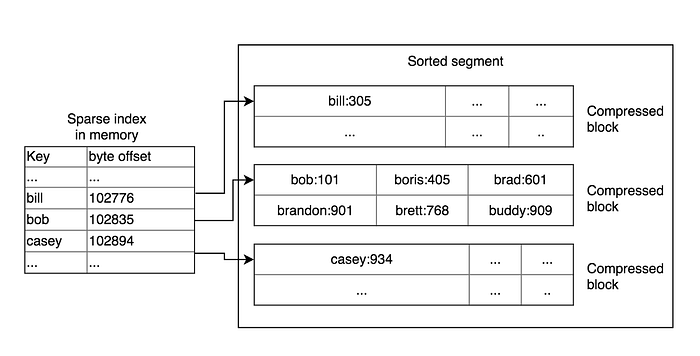
- Range queries and locality of reference
DB based on SSTable

LSM (Log structured merge tree)
Storage engines based on the concept of compaction and merging the sorted files are known as LSM (log-structured merge tree)
Performance optimization in LSM tree
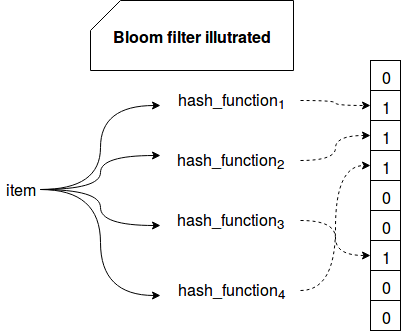
Bloom filter
If a record doesn’t exist in the database, DB has to scan through all segment files. To improve on this bloom filters are used.
Compaction strategies: Leveled vs Sized-Tired compaction
Size-tired compaction
Leveled compaction

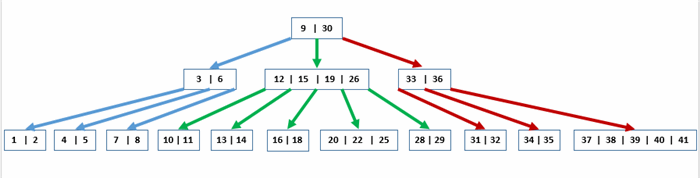
B-Tree
B Tree is a data structure used for disk access
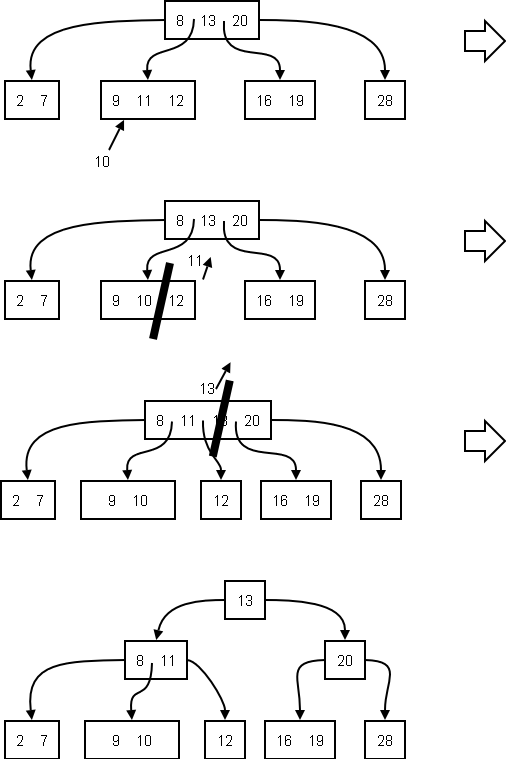
Insert
Branching Factor
The numbers of child nodes can be referred from a node of the B-tree.
Height of B-tree
Log(N), with k (branching factor) as base
B-Tree node size
4KB (can be larger as well)
Question
Given a binary tree of size 4, branching factor 500, and each node stores 4KB of data. What is the maximum of the data being stored by the binary tree?
Reliability in B- Tree
- In-place update: Create a new data node and update the pointer.
- Crash recovery: WAL (write-ahead log)
- Concurrency: Latch
Working of WAL log
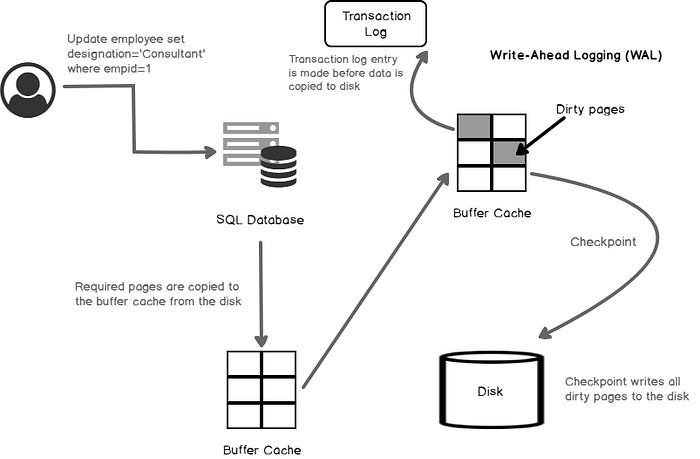
Optimization B-Tree
- Copy on write
- Abbreviated key
- Sequential access
- Sibling links
B-Tree vs LSM Tree
Thumb Rule
- LSM tree faster for writes
- B-Tree faster for the read
LSM Tree Advantages
- Faster for the write as append-only.
LSM tree downside
- The disk has a limited write capacity.
- Compaction and merging utilize some writes and hence impact external writes.
- LSM tree stores multiple copies of the same data.
Analytical processing
Commercial transactions
- Sale
- Banking
- Processing an order
OLTP ( Online Transaction Processing)
- Look for a few records and updates based on the user input.
OLAP (Online Analytical Processing)
Data analytics
- Scan over a large number of records read a few fields and calculate aggregates.
OLTP databases are highly available, hence the database administrator doesn’t allow the analytics to run long-running queries on this database. As analytical queries are expensive, scanning a large dataset which impacts the performance.
Data warehouse
It is a separate database where analysts can run queries to their content.
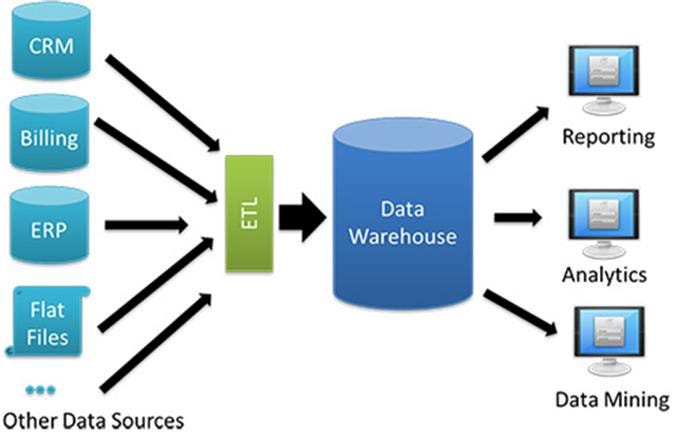
ETL
The process of getting data into the data warehouse is known as ETL (Extract Transform and Load)
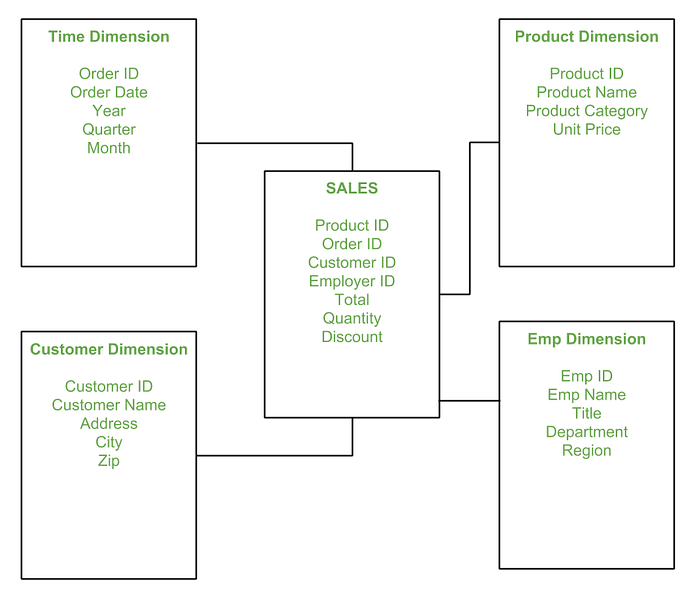
Star Schema
- Fact table: very large
- Dimension table
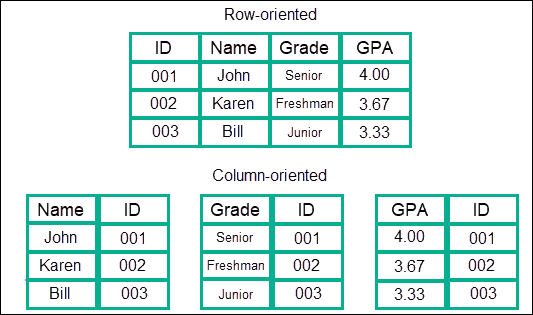
Column-oriented database
Column DB compression
