Internals of Kubernetes
K8s is a container orchestration framework.
This article primarily focuses on the internal components of the K8s cluster.
Architecture

K8s cluster consists of two principal components:
- Master Node
- Set of worker nodes
It’s the master node and a set of worker nodes only that defines a cluster of K8s.
Internal components

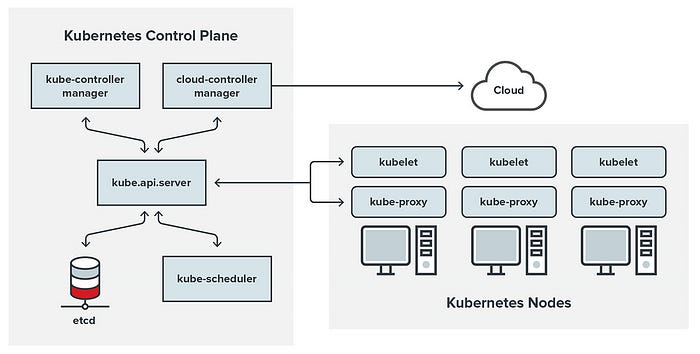
A master node has four elements:
- K8s API server
- Controller Manager
- Scheduler
- Etcd as datastore
The worker node has following parts
- Kube-proxy
- Kubelet
- Container Runtime (mostly its docker)
Check Master component status
Run following command to check if K8s master node components are running fine:
kubectl get componentstatusesoutput:

Communication across components
All components of the K8s cluster communicate only with the API server. No other components interact with each other directly.
The only component that interacts with the Etcd datastore is API server.
Distributed K8s Cluster
- K8s provides a distributed environment to your applications and a simplified interface for horizontal scaling.
- A single worker node’s components will run on an individual node. There can be multiple worker nodes.
- Master node components can run across multiple servers. A vital point to mention is that multiple instances of API server and Etcd datastore can be active at a time. But only one instance of the scheduler and controller manager can be active at a time out of multiple instances.

Runtime behavior of the components
Another interesting fact about K8s components is their run-time nature.
- All the components of the master node and Kube-proxy can run directly on the system as well as a pod.
- The only component that can’t be run as a pod is the kubelet and it should run directly on the system.
Etcd data store
- Etcd is a distributed key-value store with strong consistency. Etcd ensures strong consistency using the RAFT algorithm.
- Every K8s object (service, pod, replica-set, deployments, etc) is stored in the Etcd datastore.
- The API server is the only component in the K8s that interacts with Etcd. API server perform read/write operation on the Etcd
- All other components communicate with Etcd indirectly via the API server.
All K8s data is stored under path /registry in Etcd database.
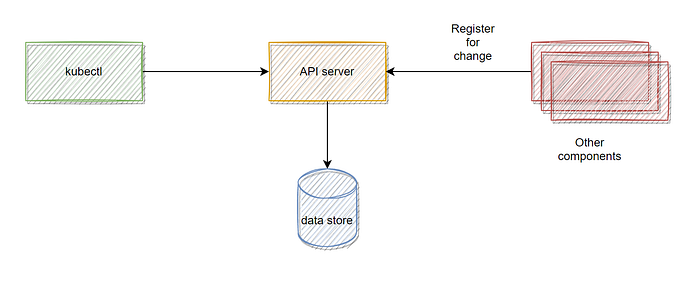
API server
- The API server is the central component to which other components in the system interact. E.g. Kubectl
- API server provides an interface for operations on the K8s cluster. API server performs validation, authZ when a client writes data to the K8s system. API server takes optimistic locking while performing the concurrent operations.
- When you request a create operation (e.g. create a pod) to the API server, the API server doesn’t perform any operation for the actual creation of the object. Instead, the API server stores the config into the Etcd store. API server allows others components like controllers to listen to these changes and react to them.
Scheduler
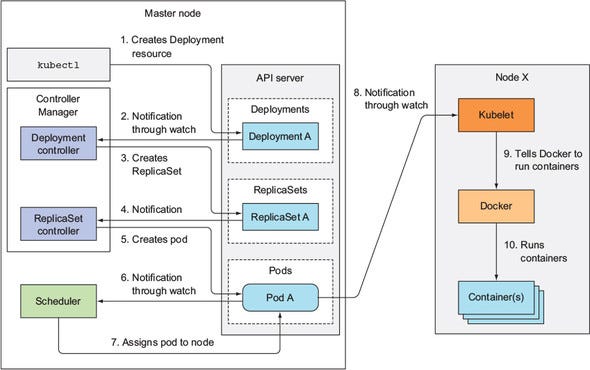
The scheduler is accountable for assigning a node to the pod when it is created via the API server.
An essential point to focus on is scheduler doesn’t create the actual pod, it just updates the configuration in the Etcd database by assigning node information to the pod definition. In simple words, it tells on which node the pod will be created.
Algorithm for scheduler:
- Fetch all the nodes.
- Filter nodes based on the pod requirements.
- Prioritize the filtered nodes and select the best node for the deployment.
- If all nodes are best, then perform a round-robin for the deployment.
You can define your scheduler in the K8s. Then in the K8s pod YAML, you have to specify your scheduler name.
Also, you can skip the scheduler component from the master node, in that case, you have to do scheduling of the pods on the nodes manually.
Controller Manager
The control manager is responsible for bringing the K8s cluster to an expected state from the current state.
The controller manager consists of the multiple controllers responsible for different operations. These controllers don’t interact with each other. For any of the controllers, you can define a custom definition as well.
Most common controllers in K8s are
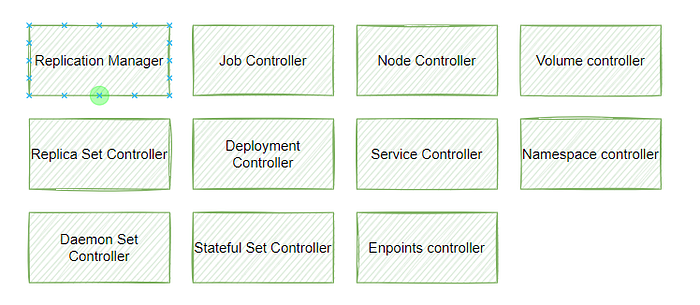
- Each controller runs a loop. In the loop, it checks the current state of the cluster, compares it with the expected state, and then takes action to bring the current state to the desired state.
- Controllers never talk to each other, they only interact with the API server by registering a watch for the changes.
Kubelet
Kubelet is a component of the worker node and is responsible for all the operations on the worker node.
Mainly it performs the following operations:
- Registration of the worker node to the K8s cluster.
- Monitor for pods that are assigned to this worker node by the scheduler.
- Monitor status, resource consumption of the pods running on the worker node.
- Liveliness probing of the container: Monitor the health of the container.
- Restart in case the container dies.
- Termination of the containers.
Kube-proxy
Kube-proxy is responsible for performing the networking operations across the nodes.
Deployment Creation flow
Networking across Pods
- A cluster network is a private network.
- Each node is assigned a range of IP addresses. These IPs are assigned to the pod running inside it.
- A unique private IP address is being assigned to each pod.
- Pods can communicate with each other via their IP addresses directly without any NAT translation.
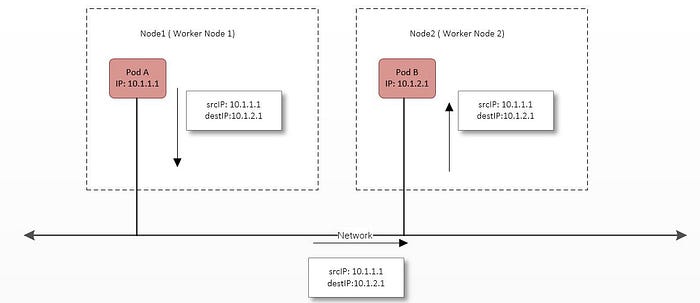
- In above diagram Node 1 get address range of 10.1.1.0/24 and Node 2 gets address range of 10.1.2.0/24.
- A packet from pod A is directly sent to the Pod B on node 2.
Pod Networking
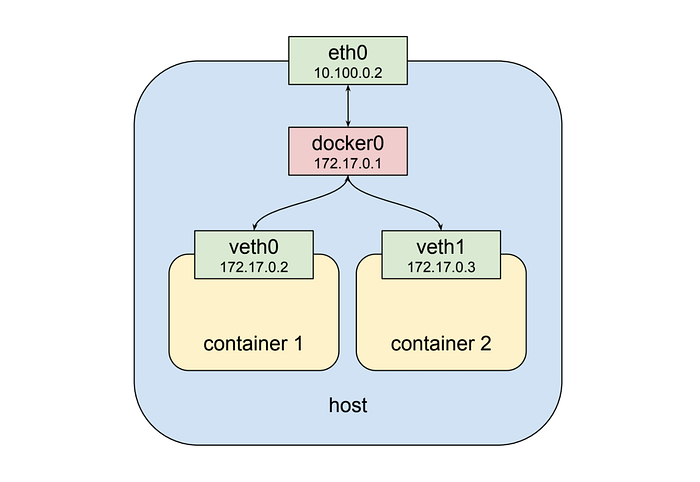
- When a worker node gets registered with the cluster, it creates a network bridge. The worker is assigned a range of IP addresses.
- Let’s assume a new worker node is assigned with an IP range is 172.17.0.0/24
- When you create a pod on the worker node, a virtual ethernet port is created per pod and assigned a private IP address from the node’s IP range. E.g. pod1 is assigned with an IP address of 172.17.0.2 and pod2 is assigned with an IP address of 172.17.0.3
- When pod 1 sends a packet to pod 2 in the same worker node, it first goes to the bridge and the bridge knows where to redirect that packet. Hence packet reaches correctly to pod 2.
Communication across multiple nodes
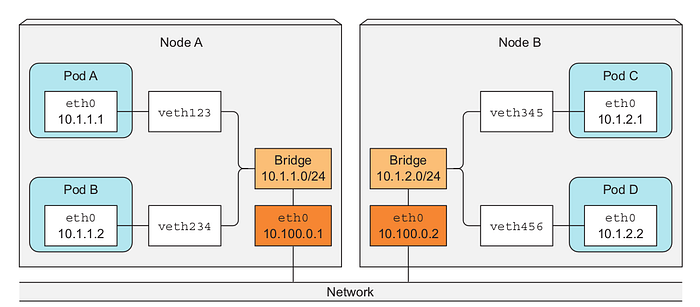
- Whenever a new worker node is being registered in the cluster, its IP address range is notified to all the worker nodes.
- When pod A (Node 1) sends a packet to pod D ( Node 2). Packet first reaches the Node 1 bridge. Node 1 bridge will redirect the packet to the Node 2 bridge. Node 2 bridge then redirect the packet to pod D.
The key point is that inter-pod communication works only underlying network is direct without any routers in between. Because routers are not cognizant of the pods and bridge IP addresses. Hence router will drop the packets.
In a truly distributed environment, it’s cumbersome to ensure the network topology without the routers. To solve this problem SDN ( software-defined network) is used after which network topology doesn’t matter.
